{kind=link}
README.md
Programmation Avancée
Réalisation d’un correcteur orthographique
Objectif
L’objectif de ce projet est de réaliser un programme qui permet de détecter dans un texte tous les mots mal orthographiés. Pour cela on utilisera un dictionnaire qui sera construit à partir d’un texte ou d’un ensemble de mots de référence.
Principe
Afin de minimiser l’espace mémoire nécessaire au stockage du dictionnaire tout en fournissant un temps de recherche bas, la structure de données que vous utiliserez sera un arbre préfixe (encore appelé trie). Il s’agit d’une structure arborescente pour laquelle des mots ayant des préfixes communs sont factorisés: chaque noeud de l’arbre est une lettre qui peut être terminale (i.e. dernière lettre d’un mot) ou pas.
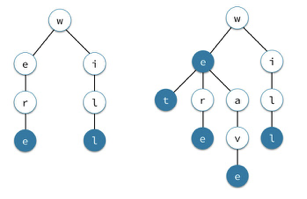
Considérons les mots: were et will. L’arbre (ou trie ) correspondant est affiché ci-dessous à gauche. Si on ajoute les mots we, wet et weave l’arbre est affiché à droite; les noeuds colorés représentant des lettres terminales.
Cahier des charges
Le travail que vous devez réaliser est le suivant:
- Définir et implémenter une structure de données permettant de stocker et de manipuler un dictionnaire sous forme d’arbre préfixe / trie.
- Charger un dictionnaire à partir d’un fichier texte de données. Ce fichier texte pouvant être un texte court, un roman ou une liste de mots. Par exemple le fichier
/etc/dictionaries-common/wordsest un dictionnaire de langue anglaise. - Analyser l’orthographe d’une phrase ou d’un texte en indiquant les nombres de mots qui ne sont pas reconnus par le dictionnaire.
Vous accorderez un soin particulier à l’ergonomie de votre programme (choix du dictionnaire, choix du texte à analyser).
Déliverables
Pour le dimanche 5 mai 23:59 (CEST) vous devrez remettre à votre tuteur un accès à votre dépôt GIT qui contiendra:
- un rapport de moins de 10 pages au format PDF contenant l’analyse de votre projet (structures de données, structuration de votre programme), les explications concernant les algorithmes principaux, le respect du cahier des charges et/ou les limitations de votre programme.
- le code source de votre projet ainsi que le Makefile permettant de le compiler automatiquement.
- un fichier README qui contiendra une description rapide de votre programme ainsi qu’un mode d’emploi.
- des fichiers de tests éventuels